

Data del RG: 17/12/2021
🔗 Paper: https://arxiv.org/abs/2111.12124
👥 Autori: Luyu Wang, Pauline Luc, Yan Wu, Adria Recasens, Lucas Smaira, Andrew Brock, Andrew Jaegle, Jean-Baptiste Alayrac, Sander Dieleman, Joao Carreira, Aaron van den Oord
📅 Data di pubblicazione: 1 Dec 2021 (v2)
🇬🇧 Version here!
TLDR: Il paper presenta un nuovo benchmark per la valutazione di rappresentazioni vettoriali di sample audio (HARES). È uno dei primi paper che indirizza esplicitamente il task di “representation learning” nel contesto audio e ne propone una valutazione abbastanza completa.
Problema: negli anni precedenti si è vista un’esplosione delle tecniche di deep learning applicate al dominio della computer vision e a quelle dell’NLP. Per quanto riguarda l’audio, ci si era concentrati soprattutto sul task di ASR (Automatic Speech Recognition) che, nonostante sia uno dei task più interessanti non è di certo l’unico e, soprattutto, è solo un task intermedio visto che la comprensione vera e propria avveniva attraverso l’uso di tecniche NLP sulle trascrizioni audio.
HARES benchmark:
Il benchmark include 12 task in totale inclusi in 3 differenti categorie:
- Environment: Audio tagging, animal sound, acoustic scenes
- Speech: Keyword, intention, language, speaker identification
- Music: instrument identification, pitch estimation and music tagging
Il principale limite del benchmark è legato alla mancanza di task di generative modeling (molto interessanti dal punto di vista audio, vedi voice cloning).
L’approccio per la valutazione dei modelli testati nel paper è il seguente:
- Pretraining del modello (supervised o self-supervised)
- Freeze del modello e training di un layer (linear) per il task considerato.
- Valutazione del modello
Questo approccio permette di valutare quanto effettivamente siano efficaci le rappresentazioni vettoriali delle reti.
Contrastive Learning
Piccola parentesi sul contrastive learning, una delle tecniche self-supervised più efficaci e in voga al momento (2021).
Il contrastive learning permette di pre-allenare reti neurali su dati senza annotazioni. Dopo una fase di pretraining possono essere specializzati utilizzando (molti) meno dati annotati con un obiettivo supervisionato.
SimCLR
Un approccio di self-supervised learning proposto originariamente per il dominio della computer vision. Visto che un’immagine vale più di mille parole:
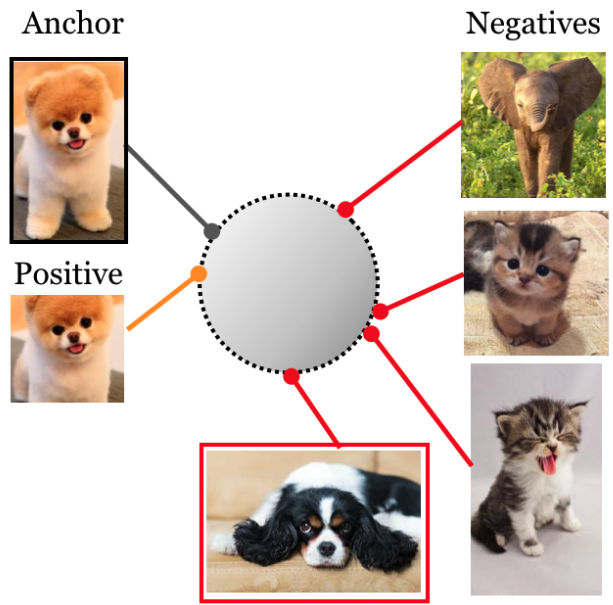
Il dataset è considerato come un insieme di esempi. Ogni esempio viene “aumentato” tramite tecniche di data augmentation (e.g., cropping, flipping…). Ciascun esempio e la sua versione aumentata vengono trattati come esempi “positivi” mentre altri esempi del dataset vengono considerati come negativi. Quelli positivi verranno “avvicinati” durante il training mentre i negativi verranno “allontanati” (nello spazio vettoriale).
Si evince come non sia necessario avere la label associata, bastano solo delle tecniche di data augmentation per crearne la versione aumentata. È però necessario avere un modo per definire gli esempi negativi (in questo caso “random sampling”).
Nel paper discusso oggi: ogni “ancora” (sample audio) viene aumentata e vengono create delle coppie positive. Facendo random sampling nel dataset vengono anche definiti degli esempi negativi. Procedendo con il training la rete viene allenata con questo obiettivo self-supervised senza avere necessità di dati annotati.
BYOL (Bootstrap Your Own Latent)
La seconda tecnica testata nel paper si chiama BYOL. A differenza della prima tecnica non è necessario selezionare degli esempi negativi. Anche in questo caso, un’immagine vale…:

Gli autori in questo caso rimuovono la necessità di esempi negativi creando un’architettura parallela.
- Si creano due istanze della stessa rete
- Una (la rete che poi verrà tenuta) vede gli esempi reali, la seconda vede gli esempi “aumentati”
- Le reti hanno due set di parametri diversi e non condivisi.
- Ad ogni ciclo di training gli esempi i pesi di ciascuna rete vengono aggiornati in modo tale da allineare le due rappresentazioni.
NB: non mi spiego come la rete non degeneri nella soluzione “ottima e assoluta” f(x)=0. Si accettano suggerimenti.
Nel paper discusso oggi: anche in questo caso vengono allenate delle reti usando questo approccio. I due approcci vengono poi confrontati con risultati interessanti.
Slowfast NFNet-F0 model:
Gli autori propongono una nuova architettura che combina due architetture precedenti:
NFNet architecture: è una famiglia di architetture che modifica ResNet originariamente proposta per la computer vision. In questa architettura viene rimossa completamente la necessità di fare batch normalization (per altro, la normalizzazione viene specificatamente investigata in una sezione del paper).
SlowFast architecture: proposta originariamente per il task di video understanding. L’ipotesi principale è che in un flusso video esistano 2 tipi di aree: aree statiche e dinamiche. Mentre le aree statiche non cambiano o cambiano poco, le aree dinamiche cambiano velocemente e contengono le informazioni più rilevanti per la comprensione. Per questo motivo questo tipo di reti propongono due routing diversi all’interno della rete per le aree statiche e dinamiche.
Architettura proposta nel paper: l’architettura che propongono gli autori gli “slow stream” contengono una capacità 8 volte maggiore (in termini di numero di canali) rispetto ai “fast stream”. Essendo basata su NFNet anche in questo caso si rimuove la batch normalization con uno speedup non indifferente.
Aspetta, cosa, canali??? Si! la rete proposta non usa self/cross/multihead/younameit-attention ma dei layer convoluzionali! E questa è una delle cose più interessanti del paper.
Risultati

La tabella riporta i risultati proposti dagli autori. A differenza degli altri appuntamenti, in questo caso è interessante analizzare i risultati. In questo caso però un paio di premesse.
Gli autori hanno testato (1) tecniche derivate dalla computer vision (ViT e CNNs) che analizzano gli spettrogrammi creati a partire dagli audio e (2) tecniche che analizzano l’audio utilizzando direttamente la waveform. Tutte le tecniche, tranne la rete da loro proposta, sono basate su architetture già esistenti (la loro ne è derivata).
Di seguito alcuni takeaways molto interessanti sui risultati:
- Tra le tecniche di pre-training basate su contrastive learning, SimCLR ha migliori performance rispetto a BYOL.
- I modelli basati su spettrogrammi vincono (e di molto) rispetto alle tecniche che analizzano le waveform. L’unico caso in cui i modelli basati su spettrogrammi sono competitivi sono i task di ASR. Questo conferma come negli ultimi anni (con i transformers) si ci sia concentrati soprattutto su questo task (la ricerca in generale) o come i tranformers non siano “adatti” a questi task (spero più nella prima).
- I modelli che vengono pre-trainati con obiettivi supervisionati portano ad un bias dell’architettura che cerca di catturare features più statiche che dinamiche (slow features instead of local traits).
- I modelli di computer vision mostrano degli scores relativamente bassi nei task legati allo speech. Il gap nei risultati è comunque molto più basso rispetto a quello che hanno i modelli basati su spettrogrammi nelle altre categorie (~40% drop).
QA Time!