
🔗 Paper: https://arxiv.org/abs/2103.03206 (ICML 2021)
👥 Autori: Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira
📅 Data di pubblicazione: 4 Mar 2021 (v1), 23 Jun 2021(v2)
‼️ Cose da sapere
- Le ConvNets (CNNs) sono delle architetture specifiche introdotte nel 1995 da Yann LeCun. La loro applicazione dal 2012 in poi ha permesso alla Computer Vision di raggiungere risultati imparagonabili ad altre tecniche (esistenti al momento).
- Le CNNs sfruttano degli “inductive bias”: una conoscenza apriori del dominio in cui saranno applicate. Per esempio le ConvNets, sfruttano la località dei pixel. Nel contesto della computer vision, ha senso avere una finestra di analisi NxN che analizza una porzione di spazio alla volta. Viceversa, questo ha poco senso nel contesto NLP, dove è più sensato avere una struttura che tiene conto della sequenza (anche in maniera bidirezionale).
- L’architettura transformers è un particolare caso di rete neurale che introduce un meccanismo di “attenzione”. Proposta inizialmente nel 2017, arrivata nei “nostri lab” nel 2018 e sfruttata in lungo e in largo in questi anni soprattutto in ambito NLP.
- I transformers sono stati applicati in Computer Vision da circa 2 anni, e hanno raggiunto ottimi risultati. In questo caso però, vista la complessità quadratica, sono riusciti a scalare solamente usando delle “patch”. In altri termini, le “parole” del transformer sono regioni dell’immagine di input (e non i singoli pixel).
- https://towardsdatascience.com/recent-developments-and-views-on-computer-vision-x-transformer-ed32a2c72654
📢 Un nuovo modello, senza inductive bias
Questo è l’obiettivo di Perceiver, proporre una rete neurale, il più possibile agnostica ai dati di input. In questo modo:
- Può essere applicata indipendentemente alle immagini, ai testi, agli audio… (you name it!)
- Può teoricamente processare più modalità alla volta (immagini e suono ad esempio)
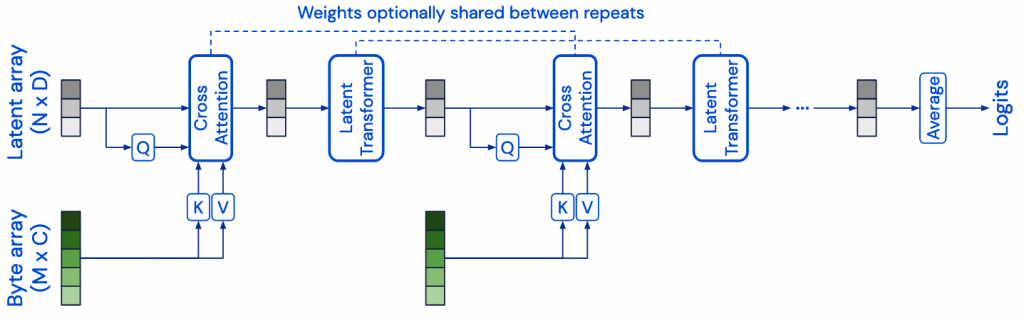
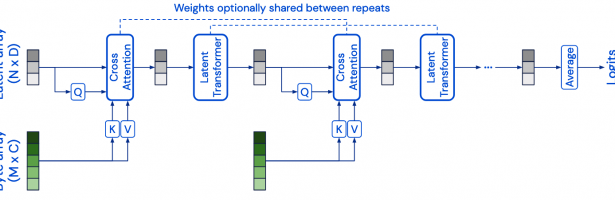
Perceiver si compone di 2 blocchi principali:
- Cross Attention: ha 2 input, un vettore (latent array) Q e il dato grezzo (byte array) proiettato in K e V. Ha come output un vettore latente della dimensionalità di Q.
- Self-attention (Transformer): riceve in input il vettore in uscita dalla cross attention (dimensione |Q|) e restituisce un’altro vettore (dimensione |Q|)
Q può essere settato per avere una dimensione agnostica all’input (iperparametro (?)). K e V invece sono dipendenti dall’input.
A cosa servono questi vettori? Mentre K, V sono componenti cardine dell’architettura di “attention”, Q viene modificato rispetto alle architetture BERT-like per introdurre dei “colli di bottiglia”. Il collo di bottiglia è il layer di cross attention, l’unico che processa direttamente l’input e ne crea una rappresentazione latente (di dimensione |Q|<<|K|) prima di processarlo con il blocco di transformer.
Perchè tutto ciò?
- Il transformer (che ha una complessità che scala quadraticamente con la dimensione di input) processerà vettori indipendenti dalla dimensione dell’input. 🎯
- La cross attention potrà avere in input una “query” che viene usata per sapere quali parti dell’input attenzionare ad ogni layer.
⚠️ Attenzione!
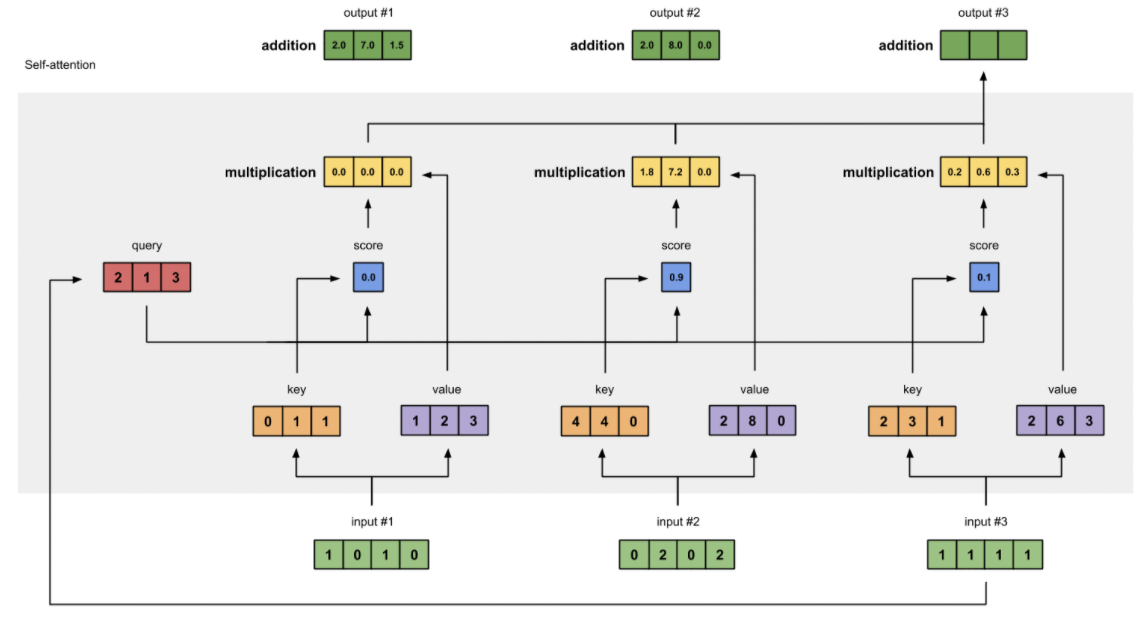
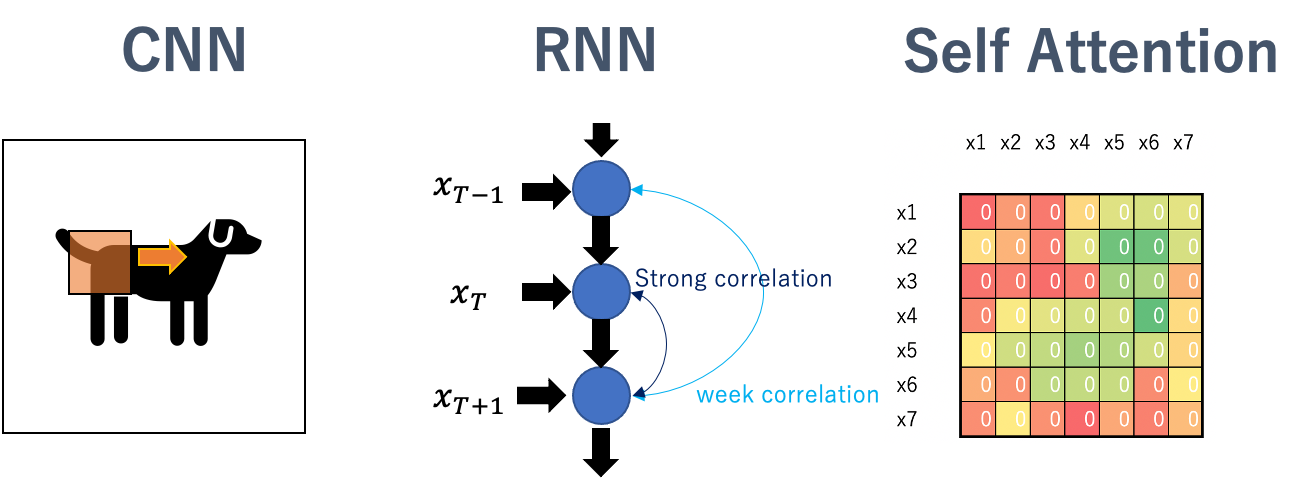
In alto la figura che illustra la self-attention, dove è possibile vedere come la complessità sia “quadratica” a causa dell’attenzione distribuita, per ciascun elemento di input verso se stesso tutti gli altri. Chiedo, per ciascun elemento (pixel, parola) quanta attenzione porre a ciascun elemento della sequenza a cui appartiene.
Nella cross attention (proposta originariamente nel paper di “Attention is all you need”, sezione decoder), l’attenzione viene “guidata” da un query vector che non sarà più della dimensione di K e V (che dipendono dagli input) ma avrà una dimensione agnostica all’input.
Per questo motivo, Q introduce un collo di bottiglia che (1) limita la complessità quadratica del meccanismo di attenzione e (2) permette al blocco di transformers di processare dimensioni “contenute” (la self-attention sarà calcolata sulla dimensionalità di Q).
So? Avendo risolto il problema della complessità quadratica della self-attention, si possono fare stack di transformers che sono indipendenti dalla dimensionalità dell’input (deeper and deeper). In aggiunta a questo, l’input che viene ricorrentemente analizzato dalla cross-attention permette di dedurre features sempre più di alto livello all’aumentare della profondità.
RNNs: gli autori spiegano come sia possibile condividere i parametri per ciascuno dei singoli blocchi dell’architettura (eccetto il primo layer). In questo caso la rete diventa molto simile a una rete ricorrente dove, la stessa cella, analizza più volte l’input.

Così come presentata, l’architettura è invariante al cambio di “posizioni” nell’input. Ma un po’ di informazioni a riguardo farebbero comodo no?
Positional Encodings: Per dare alla rete le informazioni riguardo la posizione di un elemento nel suo insieme (parola nel testo o pixel nell’immagine), i modelli basati su transformers usano i positional encodings. La sua formulazione è elegante e (a mio parere) geniale allo stesso tempo. Si usano delle “sinusoidi” di diverse frequenze per dare al modello informazioni locali e globali. Ogni elemento avrà un vettore univoco che determinerà la sua posizione ma anche “quanto” vicino si trova rispetto agli altri elementi. Gli autori ammettono che questo potrebbe essere un controsenso (introdurre un’informazione sulla posizione potrebbe essere visto come un inductive bias) MA l’idea è che, la rete avrà questa informazione, e sarà il training a decidere se e come usarla o ignorarla.
Nota: la rete non è completamente indipendente dalla dimensionalità dell’input, la cross attention ha una complessità comunque dipendente dalla dimensione dell’input (K,V).
🔬 Esperimenti
Per chi interessato possono essere analizzati nel dettaglio sfogliando la sezione 4.
TLDR: raggiungono ottimi risultati se consideriamo architetture generaliste e non specializzate (con forti inductive bias). Quando si confrontano con architetture molto specializzate (sia in contesto audio e vision) non riescono a raggiungere tali performance. Credo che sia anche normale visto che l’architettura proposta ha lo scopo di essere generalizzabile su più domini d’applicazione.
📊 Analisi
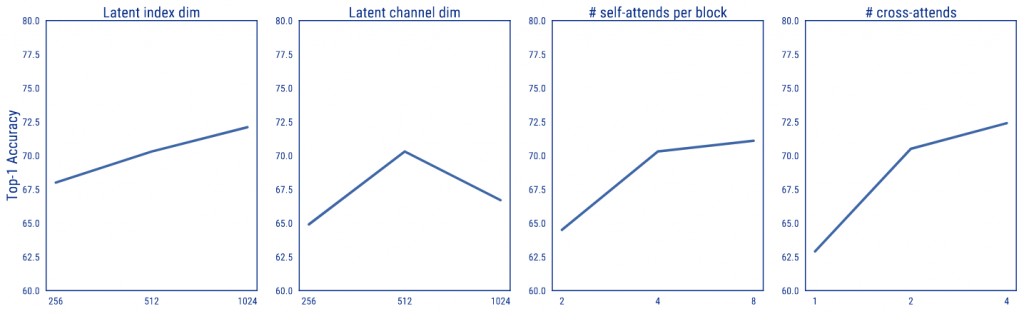
Gli autori hanno analizzato l’effetto dei parametri nell’architettura:
- 😒 Aumentando la dimensione della rete si hanno risultati migliori.
- 🤔 Aumentando la dimensione del bottleneck (Q) migliorano le performance ma aumentandola troppo si peggiora (overfitting ?)
- 🤔 Aumentare la profondità dei singoli blocchi di transformer porta benefici alle performance finali
Domande? Per esempio…
- Come fanno a analizzare i video (solo immagini) che hanno comunque dimensionalità “enormi”?
- Come fanno ad analizzare video sfruttando la multimodalità?
Per i curiosi: